What is supervised learning and how does it work?
Nov 24, 2021 · Supervised learning, one of the most used methods in ML, takes both training data (also called data samples) and its associated output (also called labels or responses) during the training process. The major goal of supervised learning methods is to learn the association between input training data and their labels.
What is supervised learning and predictive analytics?
Supervised learning is the act of training the data set to learn by making iterative predictions based on the data while adjusting itself to produce the correct outputs. By providing labeled data sets, the model already knows the answer it is trying to predict but doesn’t adjust the process until it produces an independent output.
What is supervised visitations refresher course?
Jan 27, 2022 · Supervised Learning is a machine-learning method that enables us to obtain the parameters of an algorithm from labeled training data. We have a set of input and output pairs with known labels. The goal is to learn from these examples to correctly map new inputs onto their correct outputs when given previously unseen instances.
What is an algorithm in supervised learning?
Dec 28, 2021 · In supervised learning, an algorithm is designed to map the function from the input to the output. y = f (x) [1] Here, x and y are input and output variables, respectively. The goal here is to propose a mapping function so precise that it is capable of predicting the output variable accurately when we put in the input variable.
What do you mean by supervised learning?
Supervised learning, also known as supervised machine learning, is a subcategory of machine learning and artificial intelligence. It is defined by its use of labeled datasets to train algorithms that to classify data or predict outcomes accurately.Aug 19, 2020
Which of the following are examples of supervised learning?
Some popular examples of supervised machine learning algorithms are:Linear regression for regression problems.Random forest for classification and regression problems.Support vector machines for classification problems.Mar 16, 2016
What is the purpose of supervised learning?
Supervised learning allows collecting data and produces data output from previous experiences. Helps to optimize performance criteria with the help of experience. Supervised machine learning helps to solve various types of real-world computation problems.Oct 20, 2021
What are the types of supervised learning?
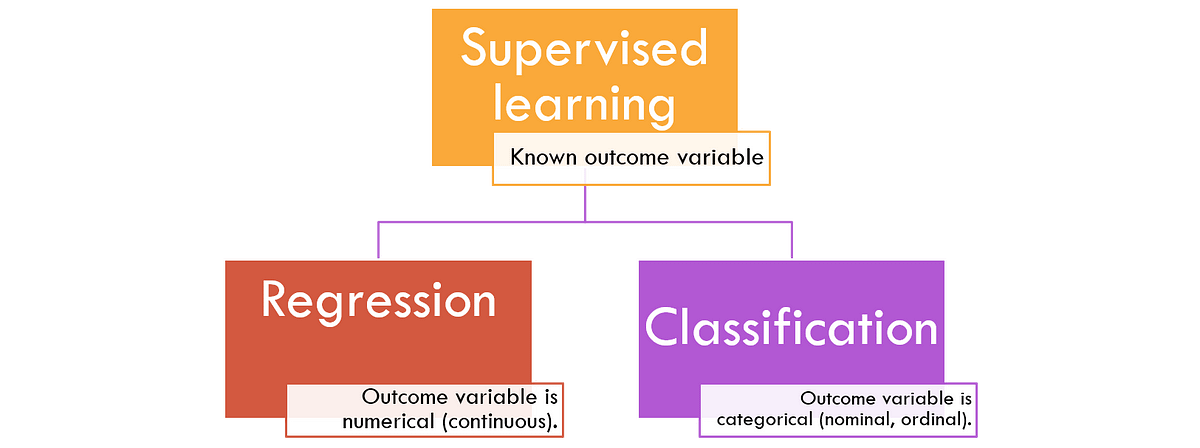
Different Types of Supervised LearningRegression. In regression, a single output value is produced using training data. ... Classification. It involves grouping the data into classes. ... Naive Bayesian Model. ... Random Forest Model. ... Neural Networks. ... Support Vector Machines.
What is the procedure of doing a supervised learning?
The steps for supervised learning are:Prepare Data.Choose an Algorithm.Fit a Model.Choose a Validation Method.Examine Fit and Update Until Satisfied.Use Fitted Model for Predictions.
What is a supervised machine learning problem?
Supervised learning is a process of providing input data as well as correct output data to the machine learning model. The aim of a supervised learning algorithm is to find a mapping function to map the input variable(x) with the output variable(y).
What are the difference between supervised and unsupervised learning?
In supervised learning, input data is provided to the model along with the output. In unsupervised learning, only input data is provided to the model. The goal of supervised learning is to train the model so that it can predict the output when it is given new data.
What are the two most common supervised tasks?
The two most common supervised tasks are regression and classification. Common unsupervised tasks include clustering, visualization, dimensionality reduction, and association rule learning.
What is supervised learning?
As the name suggests, the Supervised Learning definition in Machine Learning is like having a supervisor while a machine learns to carry out tasks. In the process, we basically train the machine with some data that is already labelled correctly. Post this, some new sets of data are given to the machine, expecting it to generate the correct outcome based on its previous analysis of the labelled data.
What is supervised learning classification?
This technique is used when the input data can be segregated into categories or can be tagged. If we have an algorithm that is supposed to label ‘male’ or ‘female,’ ‘cats’ or ‘dogs,’ etc., we can use the classification technique. Here, finite sets are distinguished into discrete labels.
What is machine learning?
Machine Learning is what drives Artificial Intelligence advancements forward. Major developments in the field of AI are being made to expand the capabilities of machines to learn faster through experience, rather than needing an explicit program every time. Supervised learning is one such technique and this blog mainly discusses about ‘What is ...
What is regression technique?
The regression technique predicts continuous or real variables. For instance, here, the categories could be ‘height’ or ‘weight.’ This technique finds its application in algorithmic trading, electricity load forecasting, and more. A common application that uses the regression technique is time series prediction. A single output is predicted using the trained data.
What is EDA in credit card fraud?
EDA is an approach used to analyze data to find out its main characteristics and uncover hidden relationships between different parameters.
What is Supervised Learning - Defintion, Types & Examples
Advantages In supervised learning, we can be specific about the classes used in the training data. That is, classifiers can be... We get a clear picture of every class defined. The decision boundary can be set as the mathematical formula for classifying future inputs. Hence, it is not required to... ...
What is Supervised Learning? - Definition from Techopedia
Supervised learning is a method used to enable machines to classify objects, problems or situations based on related data fed into the machines. Machines are fed with data such as characteristics, patterns, dimensions, color and height of objects, people or situations repetitively until the machines are able to perform accurate classifications.
Supervised Machine Learning: What is, Algorithms, Example
In Supervised learning, you train the machine using data which is well "labeled." It means some data is already tagged with the correct answer. It can be compared to learning which takes place in the presence of a supervisor or a teacher.
Understand the Supervised Learning - Machine Learning Mindset
In supervised learning, the algorithm digests the information of training examples to construct the function that maps an input to the desired output. In other words, supervised learning consists of input-output pairs for training. For testing, the ultimate goal is that the machine predicts the output based on an unseen input.
Supervised vs Unsupervised Learning: Key Differences
Unsupervised learning is a machine learning technique, where you do not need to supervise the model. Supervised learning allows you to collect data or produce a data output from the previous experience. Unsupervised machine learning helps you to finds all kind of unknown patterns in data.
Supervised Learning - Tutorialspoint
As the name suggests, supervised learning takes place under the supervision of a teacher. This learning process is dependent. During the training of ANN under supervised learning, the input vector is presented to the network, which will produce an output vector.
What is Supervised Learning in Machine Learning?
Supervised learning is used whenever we want to predict a certain outcome from a given input, and we have examples of input/output pairs. We build a machine learning model from these input/output pairs, which make up our training set. Our goal is to make accurate predictions for new, unpublished data. The Supervised machine learning algorithms ...
What is supervised machine learning class?
You will learn how to train predictive models to classify categorical outcomes and how to use error metrics to compare across different models. The hands-on section of this course focuses on using best practices for classification, including train and test splits, and handling data sets with unbalanced classes.
What is IBM Watson?
IBM. IBM is the global leader in business transformation through an open hybrid cloud platform and AI, serving clients in more than 170 countries around the world. Today 47 of the Fortune 50 Companies rely on the IBM Cloud to run their business, and IBM Watson enterprise AI is hard at work in more than 30,000 engagements.
Why is logistic regression important?
Logistic regression is one of the most studied and widely used classification algorithms, probably due to its popularity in regulated industries and financial settings. Although more modern classifiers might likely output models with higher accuracy, logistic regressions are great baseline models due to their high interpretability and parametric nature. This module will walk you through extending a linear regression example into a logistic regression, as well as the most common error metrics that you might want to use to compare several classifiers and select that best suits your business problem.
Why are ensemble models so popular?
Ensemble models are a very popular technique as they can assist your models be more resistant to outliers and have better chances at generalizing with future data. They also gained popularity after several ensembles helped people win prediction competitions. Recently, stochastic gradient boosting became a go-to candidate model for many data scientists.
What is the K nearest neighbor?
K Nearest Neighbors. K Nearest Neighbors is a popular classification method because they are easy computation and easy to interpret. This module walks you through the theory behind k nearest neighbors as well as a demo for you to practice building k nearest neighbors models with sklearn. Hours to complete.
What is decision tree method?
Decision tree methods are a common baseline model for classification tasks due to their visual appeal and high interpretability. This module walks you through the theory behind decision trees and a few hands-on examples of building decision tree models for classification. You will realize the main pros and cons of these techniques. This background will be useful when you are presented with decision tree ensembles in the next module.
Can you see lectures in audit mode?
Access to lectures and assignments depends on your type of enrollment. If you take a course in audit mode, you will be able to see most course materials for free. To access graded assignments and to earn a Certificate, you will need to purchase the Certificate experience, during or after your audit.
Introduction to Supervised Machine Learning: What is Machine Learning?
This course introduces you to one of the main types of modelling families of supervised Machine Learning: Regression. You will learn how to train regression models to predict continuous outcomes and how to use error metrics to compare across different models.
Skills You'll Learn
This module introduces a brief overview of supervised machine learning and its main applications: classification and regression. After introducing the concept of regression, you will learn its best practices, as well as how to measure error and select the regression model that best suits your data.
What is family violence?
Family violence, including domestic violence and the effects of domestic violence on children; Child abuse and neglect, including child sexual abuse; Substance abuse; Provisions of service to parents and children with mental health and developmental issues or other physical or emotional impairment;
What are the causes of grief and loss?
Grief and loss associated with parental separation and removal from the home due to child abuse and neglect; Cultural sensitivity and diversity ; Family violence, including domestic violence and the effects of domestic violence on children ; Child abuse and neglect, including child sexual abuse; Substance abuse;
Working on Supervised Machine Learning

Let us understand supervised machine learning with the help of an example. Let’s say we have a fruit basket that is filled up with different species of fruits. Our job is to categorize fruits based on their category. In our case, we have considered four types of fruits: Apple, Banana, Grapes, and Oranges. Now we will try to mention s…
Advantages
- Below are some of the advantages of supervised machine learning models: 1. User experiences can optimize the performance of models. 2. It produces outputs using previous experience and also allows you to collect data. 3. Supervised machine learning algorithmscan be used for implementing a number of real-world problems.
Disadvantages
- The following are the disadvantages given. 1. The effort of training supervised machine learning models may take a lot of time if the dataset is bigger. 2. The classification of big data sometimes poses a bigger challenge. 3. One may have to deal with the problems of overfitting. 4. We need lots of good examples if we want the model to perform well while we are training the classifier.
Good Practices While Building Learning Models
- Following are the good practices while building machine Models:- 1. Before building any good machine learning model, the process of preprocessing of data must be performed. 2. One must decide the algorithm which should be best suited for a given problem. 3. We need to decide what type of data will be used for the training set. 4. Needs to decide on the structure of the algorith…
Conclusion
- Our article has learned what is supervised learning, and we saw that we train the model using labeled data. Then we went into the working of the models and their different types. We finally saw the advantages and disadvantages of these supervised machine learning algorithms.
Recommended Articles
- This is a guide to What is Supervised Learning?. Here we discuss the concepts, how it works, types, advantages and disadvantages of Supervised Learning. You can also go through our other suggested articles to learn more – 1. What Is Deep learning 2. Supervised Learning vs Deep Learning 3. Ways to Create a Decision Tree with Advantages 4. Polynomial Regression | Uses an…
Popular Posts:
- 1. which institute is best for medical transcription course in bangalore
- 2. what is financial management course
- 3. what is the best lsat prep course to take
- 4. how to write a college course curriculum
- 5. how long is billing and coding course
- 6. how long is medical assistant course
- 7. what is pmp training course
- 8. what is a course management system
- 9. what is business management course
- 10. how long is hvac course